What is Hadoop?
Hadoop is a free, open-source software framework for distributed storage and processing of large datasets on clusters of commodity hardware. It was developed by the Apache Software Foundation and is based on the Google File System (GFS) and MapReduce.
Hadoop is designed to handle big data, which refers to extremely large datasets that cannot be processed by traditional data processing systems. Hadoop is capable of processing data in a distributed manner, which means that it can split large datasets into smaller parts and process them on different machines simultaneously. This allows Hadoop to process large amounts of data quickly and efficiently.
History of Hadoop
Hadoop was created by computer scientists Doug Cutting and Mike Cafarella, initially to support processing in the Nutch open source search engine and web crawler After Google published technical papers detailing its Google File System (GFS) and MapReduce programming framework in 2003 and 2004, Cutting and Cafarella modified earlier technology plans and developed a Java-based MapReduce implementation and a file system modeled on Google’s.
Components of Hadoop
There are several components that make up the Hadoop ecosystem, including:
- Hadoop Distributed File System (HDFS): This is the distributed file system that stores data across multiple nodes in the Hadoop cluster.
- MapReduce: This is the processing framework that allows Hadoop to process large datasets in parallel across the cluster.
- YARN: This is the resource management and job scheduling system in Hadoop that manages the processing resources in the cluster.
- Hadoop Common: This is a set of common utilities and libraries that are used by other Hadoop components.
- Hadoop Ecosystem: This includes various other components such as Hive, Pig, Spark, and HBase, which are used for data warehousing, data analysis, and real-time processing.
Hadoop Ecosystem
The Hadoop ecosystem is a collection of various open-source projects and tools that work together with the Hadoop Distributed File System (HDFS) and the MapReduce processing framework. The ecosystem includes several different projects and tools for storing, processing, and analyzing large volumes of data.
Here are some of the main components of the Hadoop ecosystem:
- Apache Hive: This is a data warehousing and SQL-like query language that allows users to extract and analyze data stored in HDFS.
- Apache Pig: This is a high-level data flow language and execution framework that is used to process and analyze large datasets.
- Apache HBase: This is a NoSQL database that is used for real-time data access and processing.
- Apache Sqoop: This is a tool used for importing data from relational databases such as MySQL and Oracle into Hadoop.
- Apache Flume: This is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data.
- Apache Kafka: This is a distributed streaming platform that is used for building real-time data pipelines and streaming applications.
- Apache Spark: This is a fast and general-purpose cluster computing system that is used for processing large datasets in memory.
- Apache Storm: This is a distributed real-time processing system that is used for streaming large volumes of data.
- Apache Oozie: This is a workflow scheduler system that is used for managing Hadoop jobs.
- Apache Zeppelin: This is a web-based notebook that is used for data exploration, visualization, and collaboration.
- Apache Flink: This is a distributed processing system for stream and batch data processing.
There are many other projects and tools in the Hadoop ecosystem, and new ones are constantly being added. The main goal of the ecosystem is to provide users with a wide range of tools and options for storing, processing, and analyzing large datasets.
Hadoop File System
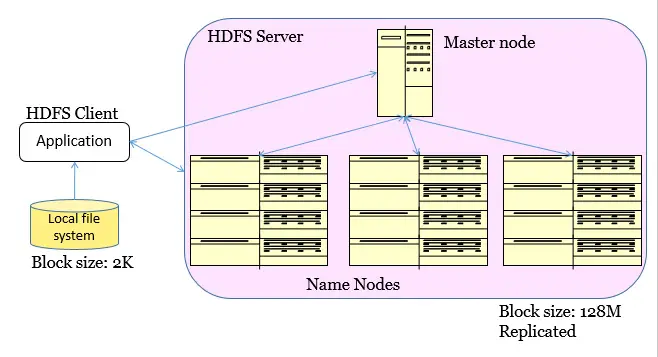
- Goal
- global view
- make huge files available in the face of node failures
- Master Node (meta server)
- Centralized, index all chunks on data servers
- Name Nodes (data server)
- File is split into contiguous chunks, typically 16-128MB.
- Each chunk replicated (usually 2x or 3x).
- Try to keep replicas in different racks.
Fault Tolerance
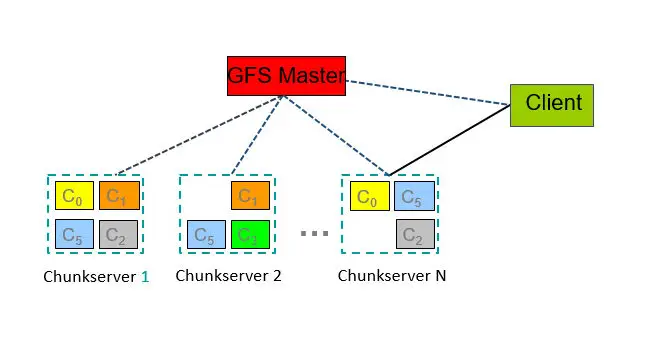
A HDFS instance may consist of thousands of server machines, each storing part of the file system’s data. Since we have huge number of components and that each component has non-trivial probability of failure means that there is always some component that is non-functional.
- Reactive way
- Worker failure
- Heartbeat, Workers are periodically pinged by master
- NO response = failed worker
- If the processor of a worker fails, the tasks of that worker are reassigned to another worker.
- Master failure
- Master writes periodic checkpoints
- Another master can be started from the last check pointed state
- If eventually the master dies, the job will be aborted
- Worker failure
- Proactive way (Redundant Execution)
- The problem of “stragglers” (slow workers)
- Other jobs consuming resources on machine
- Bad disks with soft errors transfer data very slowly
- Weird things: processor caches disabled (!!)
- When computation almost done, reschedule in-progress tasks
- Whenever either the primary or the backup executions finishes, mark it as completed
- The problem of “stragglers” (slow workers)
- Input error: bad records
- Map/Reduce functions sometimes fail for particular inputs
- Best solution is to debug & fix, but not always possible
- On segment fault
- Send UDP packet to master from signal handler
- Include sequence number of record being processed
- Skip bad records
- If master sees two failures for same record, next worker is told to skip the record