
Server rack setup for Hadoop cluster
This rack setup is idel for Hadoop cluster setup, by which cluser become more fault tolerant.
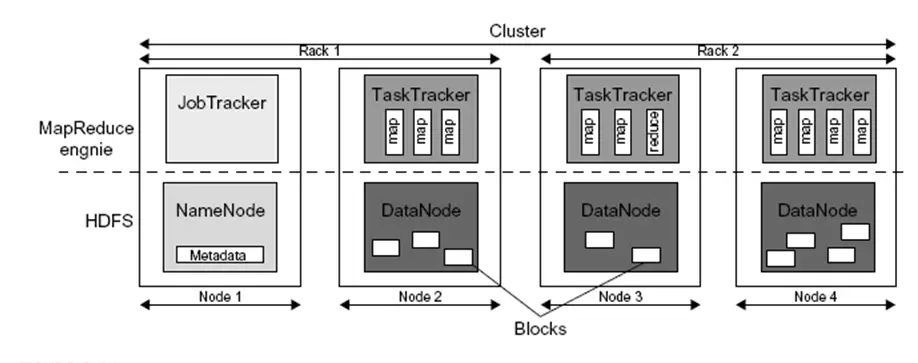
The highest layer of Hadoop is the MapReduce engine that deals with the information stream and control stream of MapReduce occupations over conveyed processing frameworks. Figure shows the MapReduce engine architecture helping out HDFS. Like HDFS, the MapReduce engine also has a master/slave architecture consisting of a single JobTracker as the master and a number of TaskTrackers as the slaves (workers).
The JobTracker manages the MapReduce job over a cluster and is responsible for monitoring jobs and assigning tasks to TaskTrackers. The TaskTracker manages the execution of the map and/or reduce tasks on a single computation node in the cluster. Each TaskTracker node has a number of simultaneous execution slots, each executing either a map or a reduce task. Slots are defined as the number of simultaneous threads supported by CPUs of the TaskTracker node.
For example, a TaskTracker node with N CPUs, each supporting M threads, has M * N simultaneous execution slots [66]. It is worth noting that each data block is processed by one map task running on a single slot. Therefore, there is a one-to-one correspondence between map tasks in a TaskTracker and data blocks in the respective DataNode.
