MapReduce Operation step by step | with example
—MapReduce is a programming model Google has used successfully is processing its “big-data” sets (~ 20 petabytes per day). MapReduce requires a distributed file system and an engine that can distribute, coordinate, monitor and gather the results. Hadoop provides that engine through (the file system we discussed earlier) and the JobTracker + TaskTracker system.
JobTracker is simply a scheduler. TaskTracker is assigned a Map or Reduce (or other operations); Map or Reduce run on node and so is the TaskTracker; each task is run on its own JVM on a node.
Map invocations are distributed across multiple machines by automatically partitioning the input data into a set of M splits.
Reduce invocations are distributed by paritioning the intermediate key space into R pieces using a hash function: hash(key) mod R.
R and the partitioning function are specified by the programmer.
When the user program calls the MapReduce function, the following sequence of actions occurs :
- The MapReduce library in the user program first splits the input files into M pieces – 16 megabytes to 128 megabytes (MB) per piece. It then starts up many copies of program on a cluster of machines.
- One of the copies of program is master. The rest are workers that are assigned work by the master.
- A worker who is assigned a map task :
- reads the contents of the corresponding input split.
- parses key/value pairs out of the input data and passes each pair to the user – defined Map function.
- The intermediate key/value pairs produced by the Map function are buffered in memory.
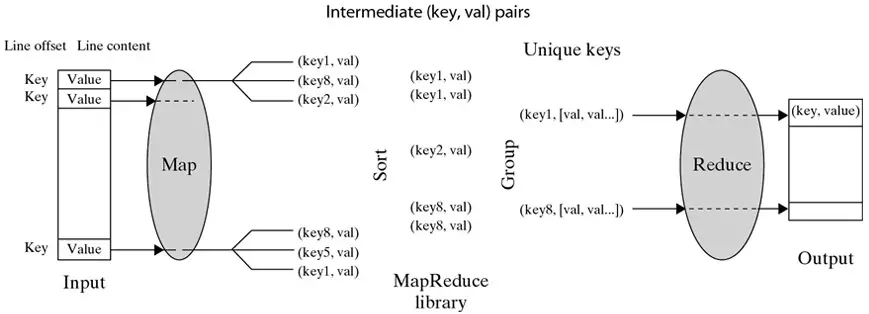
- The buffered pairs are written to local disk, partitioned into R regions by the partitioning function. The location of these buffered pairs on the local disk are passed back to the master, who forwards these locations to the reduce workers.
- When a reduce worker is notified by the master about these locations, it reads the buffered data from the local disks of the map workers. When a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together.
- The reduce worker iterates over the sorted intermediate data and for each unique intermediate key, it passes the key and the corresponding set of intermediate values to the user’s Reduce function. The output of the Reduce function is appended to a final output file.
- When all map tasks and reduce tasks have been completed, the master wakes up the user program. At this point, MapReduce call in the user program returns back to the user code. After successful completion, output of the mapreduce execution is available in the R output files.